Pending Cases and Forecasts
1. Open cases are part of the analysis, not excluded from it
A pending row contributes the information T > current_age. In survival-analysis terms, that is right censoring, not missingness. Discarding these rows would bias the published curves toward faster cases and erase most of the visible signal about the slow tail. That is why this project publishes Kaplan-Meier curves, censored parametric fits, and a conditional prediction table for open cases.
2. The current open tail is broader than a single-month anomaly
As of 2026-03-15, all 18 pending rows in the filtered dataset are post-interview cases. December 2025 remains the single largest pending cluster, but the current tail is not confined to December.
| Interview month | Pending cases | Days since interview in current snapshot |
|---|---|---|
| 2025-05 | 2 | 291, 314 |
| 2025-10 | 1 | 151 |
| 2025-11 | 2 | 122, 131 |
| 2025-12 | 7 | 87, 87, 90, 95, 95, 95, 95 |
| 2026-01 | 5 | 46, 52, 59, 59, 67 |
| 2026-02 | 1 | 24 |
This matters because an earlier community hypothesis could be summarized as “December 2025 may be unusually sticky after interview.” The current repo snapshot still supports watching December closely, but it now also contains a small number of much older unresolved cases. The active question is no longer just whether one interview month slowed down; it is whether the post-interview tail has become structurally wider than the fast majority would suggest.
3. Why the site publishes both baseline and USCIS-updated total-time curves
The empirical KM curve is driven entirely by the observed sample. The optional USCIS-tail mixture adds external anchors at day 300 (80%) and day 629 (93%) so that far-tail predictions are not unrealistically optimistic when the crowdsourced sample is still small.
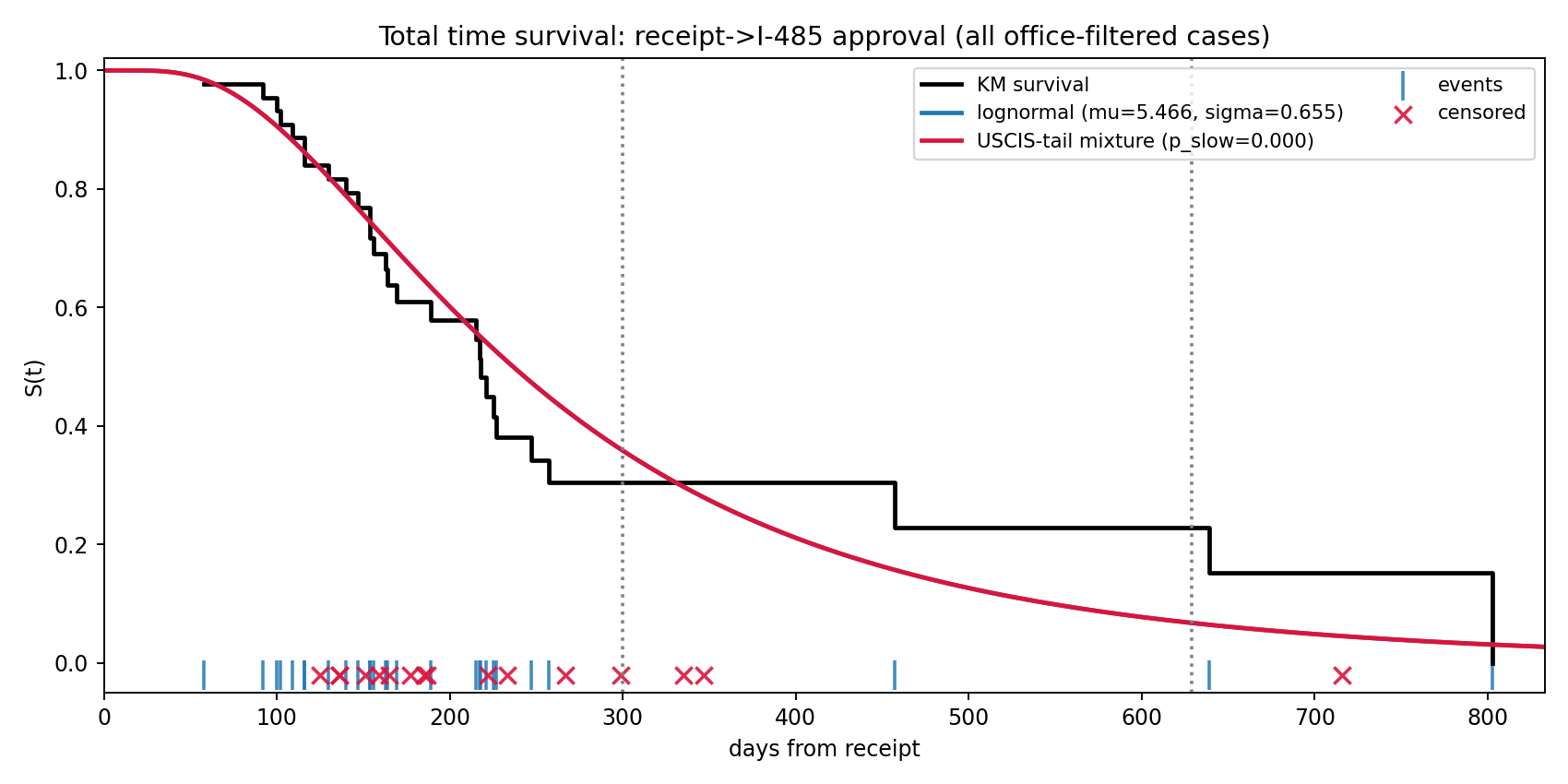
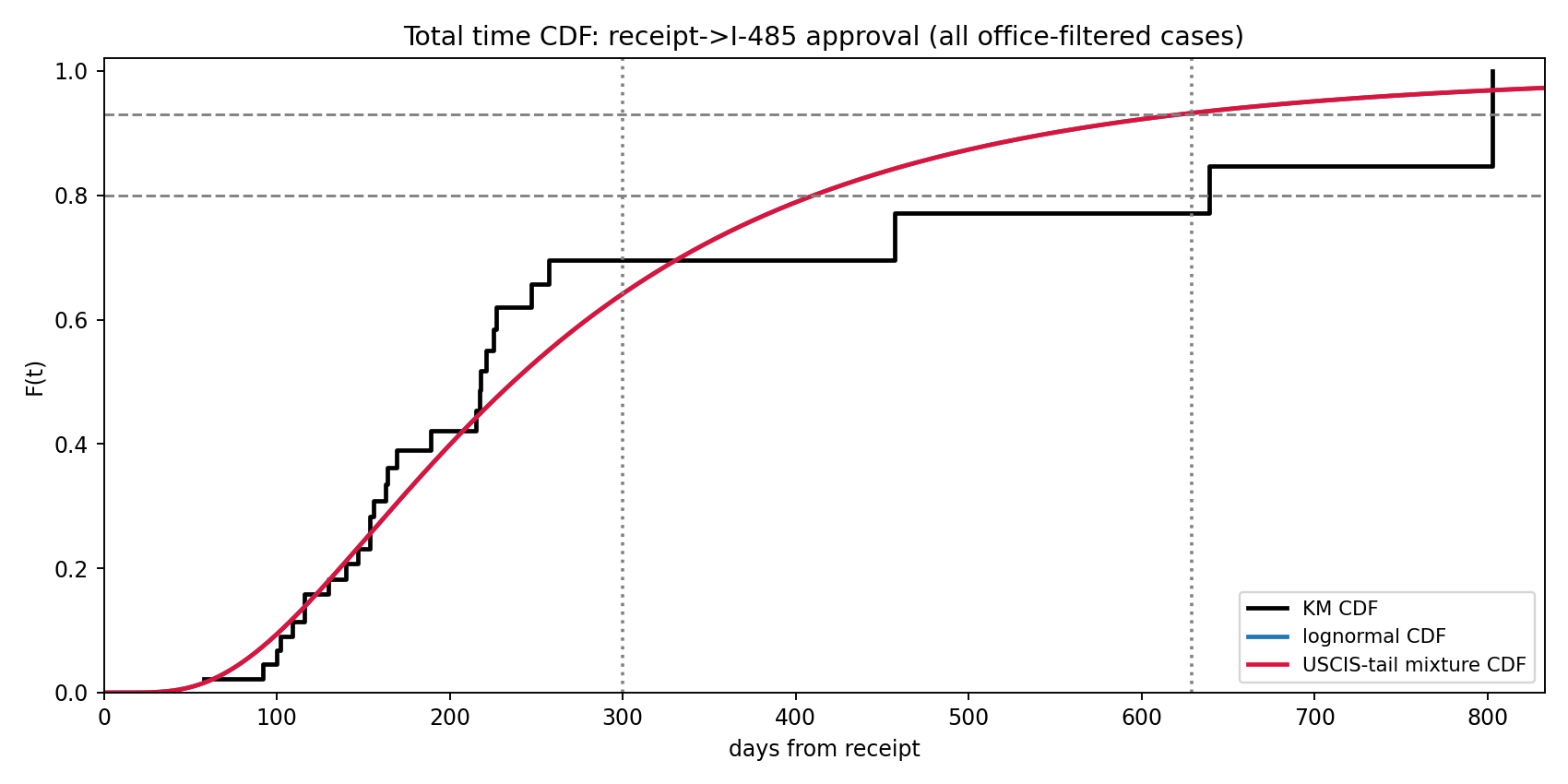
In the current snapshot, the all-case fitted baseline is already slower than the day-300 USCIS anchor, so the mixture calibration falls back to p_slow = 0. Operationally, that means the “updated” total-time probabilities coincide with the baseline for this run. The USCIS-tail machinery remains useful because future snapshots can still enter the regime where an explicit slow component is needed.
4. How to use pending_predictions.csv
The prediction table at results/latest/tables/pending_predictions.csv reports conditional probabilities for each pending case with a known receipt date across all receipt years, including:
receipt_year,interview_year, andinterview_monthfor contextt0_days_since_receiptandt0_days_since_interviewat analysis time- approval within 30 days from the current age
- approval within 60 days from the current age
- approval by day 300 from receipt
- approval by day 629 from receipt
- posterior probability of belonging to the modeled slow regime
Read these as model-based conditional probabilities, not individual case promises. The important change is scope: the table is no longer restricted to a fixed 2025 receipt subset, so older pending cases and any future 2026-receipt cases are included automatically whenever their receipt dates are known. In snapshots where the USCIS-tail calibration collapses to p_slow = 0, the baseline and updated columns will match numerically.
For fitting details and parameterization, see Methods and Assumptions and Caveats.